Understand Portworx Backup
Portworx Backup is a Kubernetes backup solution that allows you to back up and restore applications and their data across multiple clusters. Portworx Backup works with Portworx Central, allowing you or any other approved users to manage multiple clusters and their backups from a single UI. Under this principle of multi-tenancy, authorized users connect through OIDC to create and manage backups for clusters and applications which they have permissions without needing to go through an administrator.
Portworx Backup architecture
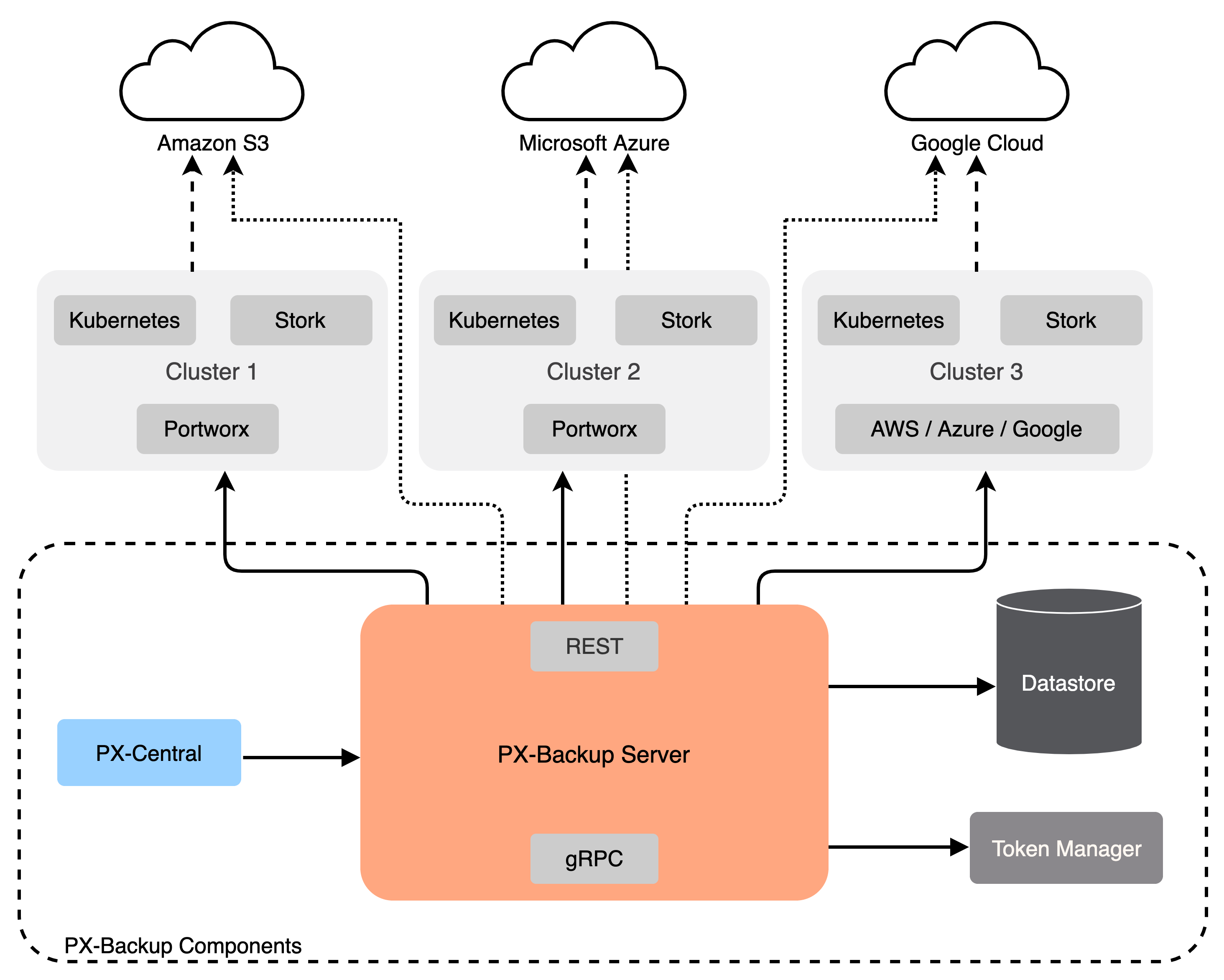
Portworx Backup is compatible with any Kubernetes cluster, including managed and cloud deployments, and does not require Portworx Enterprise to be installed. Portworx Backup integrates with the following major block storage providers:
- Amazon EBS
- Google Persistent Disk
- Azure Managed Disks
- Portworx PX-Store
Portworx Backup is capable of backing up the following Kubernetes resources:
- Persistent Volume (PV)
- Persistent Volume Claim (PVC)
- Deployment
- StatefulSet
- ConfigMap
- Service
- Secret
- DaemonSet
- ServiceAccount
- Role
- RoleBinding
- ClusterRole
- ClusterRoleBinding
- Ingress
Understand how Portworx Backup works
Portworx Backup provides namespace and label selectors, allowing you to create granular backups of the application you want. You can back up an entire namespace, or you can use label selectors to select only certain resources to back up. This selection method also helps preserve associated configuration and pod data, ensuring that your backups work properly once restored. For example, Portworx Backup can back up a MySQL deployment containing pods, PVCs, and volumes tagged with an app = mysql label. Given this system, Portworx Backup can back up stateful applications as easily as stateless ones.
You can schedule backups by creating an independent schedule policy that defines when backups run and how many rolling copies they keep, and you can associate this schedule policy with as many backups as you want.
Avoid manual prep-work and minimize interruptions to your cluster associated with backup tasks by creating rules that run before and after backups are taken. As with schedule policies, you can associate rules with multiple backups.
Portworx Backup components
To use Portworx Backup, it is helpful to understand the components within it. These components enable you to perform backup and restore operations:
Portworx Backup server
This is a gRPC server that implements the basic CRUD operations for the following Portworx Backup objects:
- Cluster
- Backup location
- Cloud credential
- Schedule policy
- Backup
- Restore
- Backup schedule
Application clusters
A cluster in Portworx Backup is any Kubernetes cluster that Portworx Backup makes backups from or restores backups to. Portworx Backup supports any Kubernetes cluster that is network accessible. With Portworx Backup, you can monitor, backup, and restore across all of your Kubernetes clusters. Application clusters:
- Lists all applications and resources available on the cluster, which you can choose to back up.
- Creates or manages stork resources on the cluster. Portworx Backup Server communicates with stork to create application-level backups by creating the BackupLocation and ApplicationBackups CRDs. Stork monitors these CRDs on each user’s cluster. Portworx Backup Server also monitors the status of ApplicationBackups and ApplicationRestores on these clusters.
Datastore
Database where the Portworx Backup stores objects related to the cluster such as backup location, schedule policies, backup, restore, and backup schedule. Portworx Backup uses MongoDB as the datastore from the 2.0.0 version.
Token Based Authentication
Portworx Backup Server communicates with an external service (Okta, KeyCloak, and so on) to validate and authorize tokens that are used for the API calls.
Backups
Backups in Portworx Backup contain backup images and configuration data. You can attach schedule policies to run them at designated times and keep a designated amount of rolling backups, and attach rules to perform commands before or after a backup runs.
Backup locations
Backup locations are object stores you have added to Portworx Backup. Portworx Backup stores backups on any compatible object storage:
- AWS S3 or compatible object stores
- Azure Blob Storage
- Google Cloud Storage
A backup location is not tied to any particular cluster, and can be used to trigger backups and restores on any cluster. Similar to clusters, an administrator or user can create a backup location. The Portworx Backup server stores information about the create request in the Datastore.
Restores
Restore your backups to the original cluster or different clusters, replace applications on the original cluster or restore to a new namespace. Perform partial restores to selected namespaces from the backup.
Schedule Policies
Create schedule policies and attach them to backups to run them at designated times and keep a designated amount of rolling backups.
Rules
Use rules to create commands which run before or after a backup operation is performed.
Application view
You can interact with Portworx Backup through a central application view. From here, you can see all the resources currently on your cluster, filter them by namespace and labels, and create a backup.
Get Started
Perform the following tasks to get started with Portworx Backup and perform your first backup: